文章来源:VAST 2019
报告人:王智勇
mail: zerowangzy@zju.edu.cn
时间:2020-06-11 下午 4 点
地点:钉钉线上会议
1. 简介
1.1 作者介绍

几位作者除了大家都熟悉的 VCG 大神的 Hanspeter Pfister,其他几位的本职研究和 NLP 相关。他们也几乎都和哈佛有关,一作 Sebastian Gehrmann,是哈佛毕业的博士,现在在 google AI 做可控和可解释的深度学习,本文其实就是一种可控深度学习的研究成果;二作 Hendrik Strobelt 是 IBM 的研究员,也在哈佛做过博士后,本质做 NLP 研究;Hanspeter 是可视化的大神,就不多介绍了,本文通讯作者 Alexander 是康奈尔的副教授,14 年 MIT 毕业的博士,本职研究是 NLP,但也拿过 VAST 的 best paper,成果颇多。
1.2 内容简介
问题描述
在深度学习的发展过程中,研究者为了提高性能和速度,模型变得越来越复杂,动辄上亿的参数量。着导致深度学习的过程难以解释、分析和可视化。而且用户要使用这样的黑盒,就得完全放弃自己的控制权,被迫去相信和依赖模型。然而模型往往会产生一些无法预测、难以解释的错误。
这篇文章想解决的问题是:如何让用户重新获得对推理过程的控制权
解决思路
作者认为,如果能够通过某种方法,通过对模型推理的过程进行解释和干预,将模型作为团队中的一员,让人和模型合作式的完成任务,人就能重新获得对推理过程的控制。
因此,作者提出了一套理论概念:Collaborative Semantic Inference(CSI),来尝试系统化地阐述,如何达到将人和模型协作起来完成任务。同时,作者也给出了一个 CSI 的 use case,一个文本总结系统,也证明这套方法的有效性。
2. 如何将模型和交互结合
2.1 机器学习可视化分类
文章先针对过去机器学习可视化的成果进行了一个分类。作者主要从 2 个维度对现有成果进行分类:
a. 按照模型和交互的结合程度
可分为三类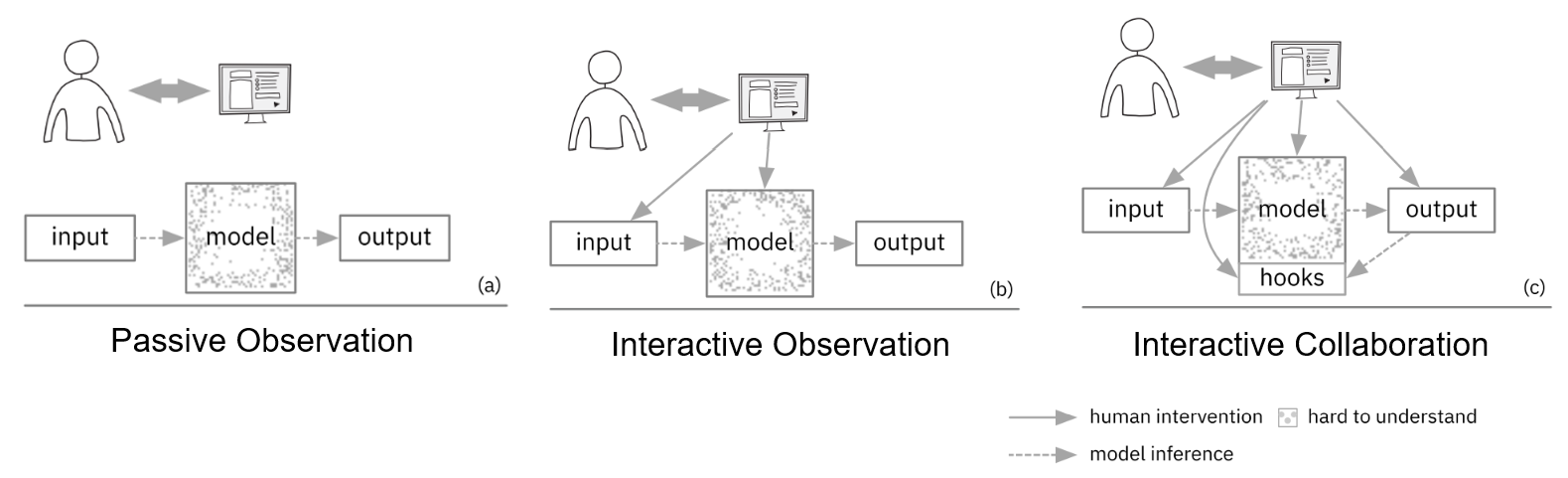
- Passive Observation
用户和模型之间没有交互:模型作为数据的上游,向可视化系统提供数据,可视化系统并不会对模型造成任何影响。用户对模型仅能进行观察。可视化和模型之间无耦合。
- Interactive Observation
用户能够在一定程度上进行交互:用户可以通过交互改变模型的输入数据,从而改变模型在训练或推理过程中产生的数据。同样,用户仅能对模型进行观察,而无法做到对模型进行修改。可视化和模型之间弱耦合。
- Interactive Collaboration
用户能够通过交互,来改变模型的行为,进而能够和模型协作完成某些任务。例如在训练过程中,用户可以交互地修改训练数据的标签,从而影响模型参数。CSI 就是在这一类别内。可视化和模型之间强耦合,需要对模型、交互、可视化进行共同设计(co-design)。
b. 按照可视化的目标来分
可以分成是对模型进行理解和修改的,还是对决策过程进行理解和修改的。
- Model Understanding / Shaping
首先,第一类可视化,目标是对模型进行理解和修改,它不涉及模型是如何进行推理的,而是单纯对模型本身进行可视化。例如对 loss、激活值、模型参数、梯度值、模型中高维张量的降维投影等,都是这类可视化。
- Decision-Understanding / Shaping
大部分的机器学习可解释性的工作都是这一类,它并不阐述模型内部的各种数值,而是以帮助人理解为目的,去分析模型是如何进行推理。例如卷积网络在对一张猫的图片分类时,通过对卷积层的激活值可视化,发现猫的耳朵激活程度较高,进而我们可以理解模型是通过猫的耳朵做推理决策的。
2.2 实例分析
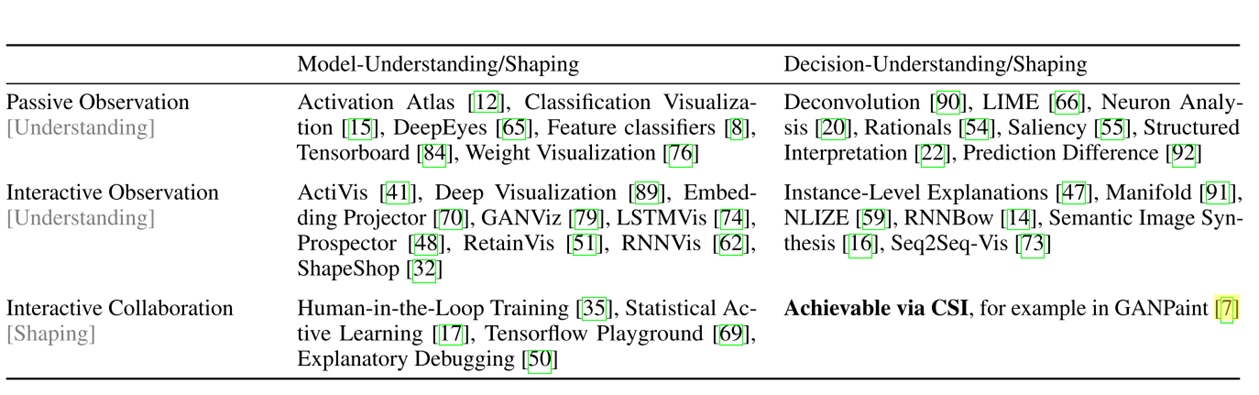
作者给出了上图这样的二维表格,表格内填有相应类型的可视化工作。我们每一种类型挑选一个来简要介绍一下
1. Passive Observation & Model Understanding
以 TensorBoard 为例: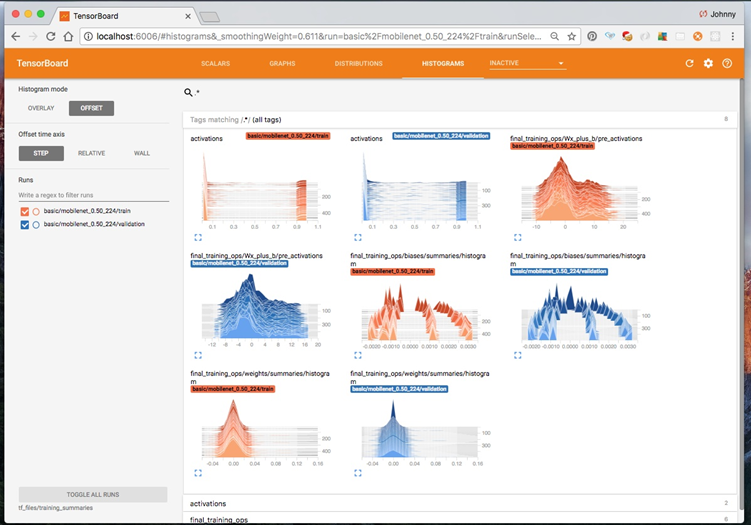
tensorboard 应该是大家最熟悉的一个机器学习可视化工具了,它单纯的接受模型在训练过程中产生的各种数据,并不能反向影响模型行为,因此它是 Passive Observation 的。其次,它的可视化主要围绕模型本身的各类数值指标,并不帮助用户理解模型的决策,因此它是 Model Understanding 的工作。
2. Passive Observation & Desicion-Understanding
此类成果用户同样只能对上游的数据进行观测,但可视化是服务于对模型决策/推理过程进行理解的。
例如 Deconvolution:
Deconvolution 能够根据卷积神经网络推理的数据,可视化出输入图片在每一层卷积层上,模型看到了什么,从而帮助用户理解模型的决策过程。
3. Interactive Observation & Model-Understanding
例如 ActiVis:
Facebook 研发的 ActiVis 在功能上相比 TensorBoard,多了数据实例选择的交互。用户可以通过实例选择器,选择喂给模型的输入数据,模型会产生新的数据给系统做可视化。
4. Interactive Observation & Decision-Understanding
如同样由这篇文章的几位作者的工作成果:Seq2Seq-Vis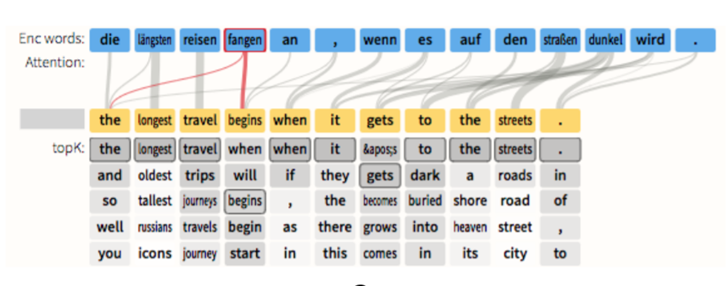
Seq2Seq-Vis 是针对 Seq2Seq 模型可解释性的可视化工具。它将 output 和 input 之间的 attention 可视化出来,来解释模型是如何通过在 input 中推理到当前结果的。同时它也具备用户选择输入数据的交互。
5. Interactive Collaboration & Model-Shaping
以大家最熟悉的 TensorBoard-Playground 为例: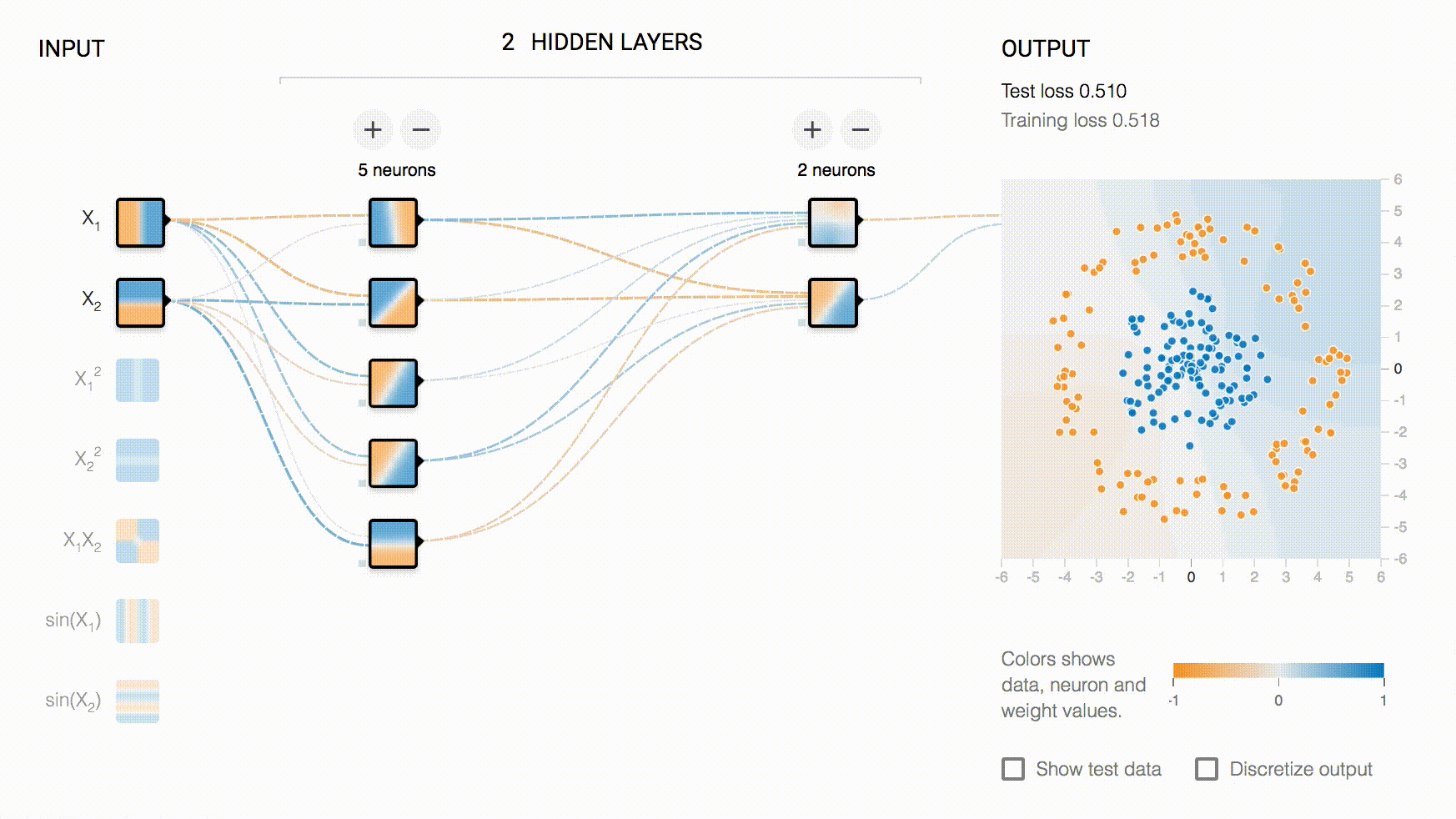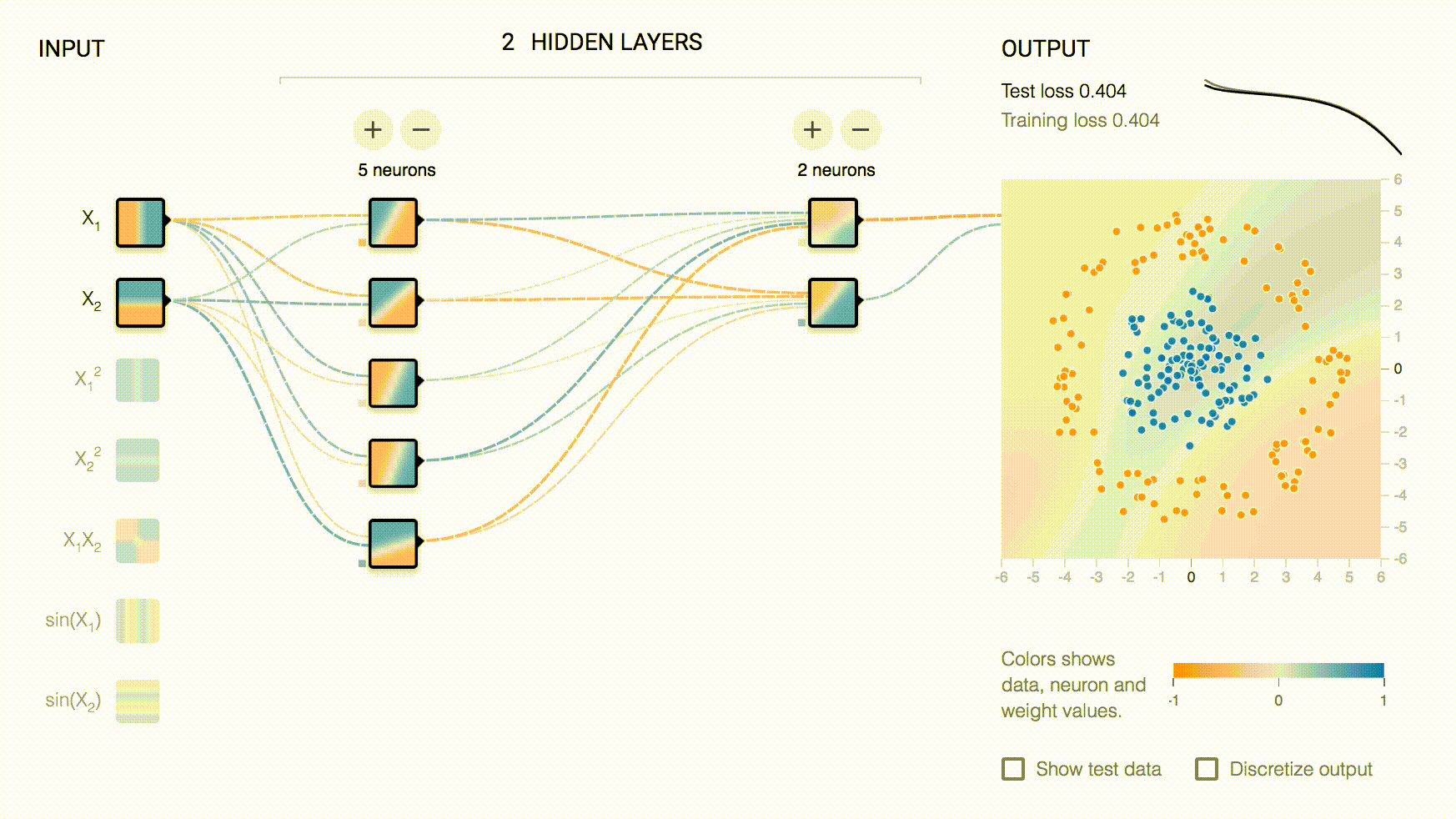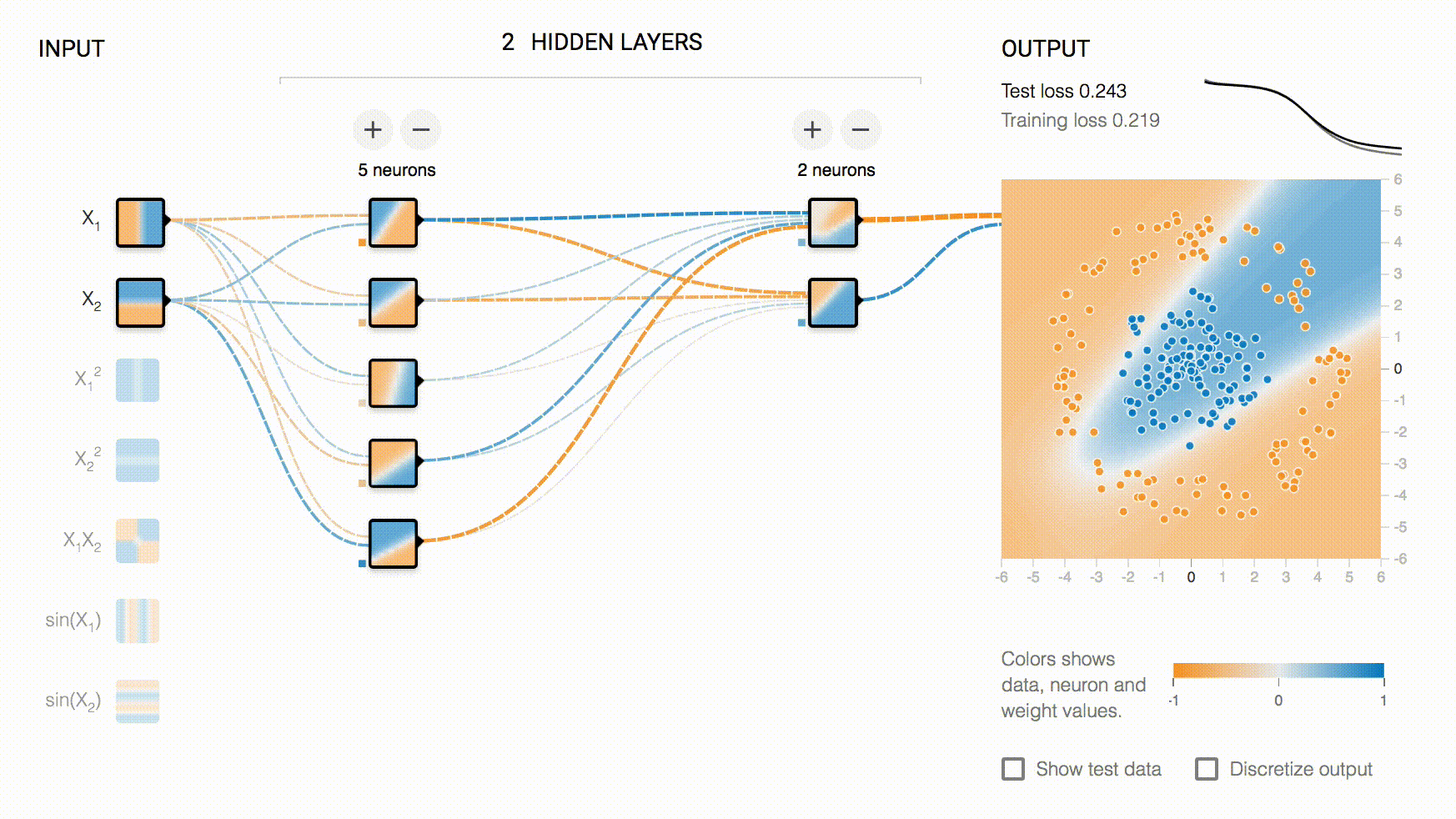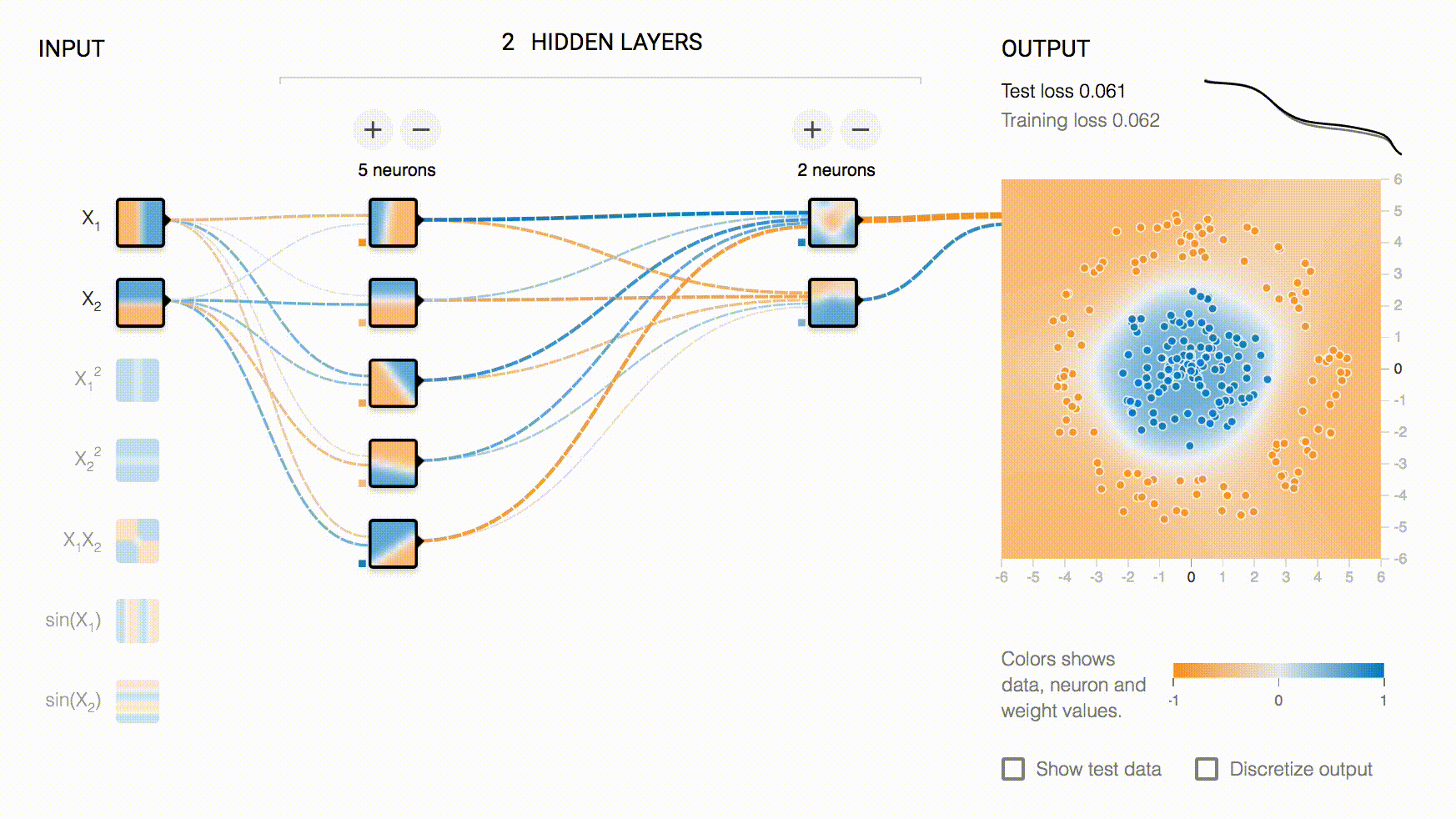
playground 的交互级别不仅仅是选择输入数据,还可以通过交互,改变模型的结构(增加删除层和神经元),因此它属于 Interactive Collaboration,同时,它是对模型直接进行修改,而不是对决策进行修改,所以是 Model-Shaping。
6. Interactive Collaboration & Decision-Shaping
本文的重点,做到这一点,就可以认为是 CSI 了。
过去的工作成果中,也有些工作可以被认为是这一类的。例如 GANPaint
GANPaint 是港科大研发的,曾经也被刷爆朋友圈。用户只需要选择一种对象,比如树,然后在图片就能直接画出相应的对象。
它背后的原理可以理解为:先对模型中的神经元进行语义的提取,找到哪些神经元控制哪些场景,比如某 100 个神经元控制树的生成。然后将这些神经元作为 hook,暴露在模型之外,用户能够通过交互修改这些神经元,从而影响模型的推理过程,改变模型的输出。
这种就属于 CSI 思想。接下来我来介绍到底什么是 CSI。
3 CSI
3.1 什么是 CSI
如前文所述,其实符合 Interactive Collaboration 且是服务于 Decision-Shaping 的可视化,都可以理解为是 CSI。
根据文章中的描述,CSI 可解释为:模型预测和用户对模型进行干预交替进行的推理过程。它包括 forward 和 backward。
利用 CSI 的推理过程是:
模型推理 —> 用户对模型的输出不满意,用户查看模型推理过程(backward) —> 用户改变模型推理过程,模型重新进行推理(forward)
但是要如何实现这一点呢?
3.2 CSI 的实现思路
要实现 CSI,需要解决的核心问题,就是如何去控制模型的推理过程。模型里拥有海量的参数,能对这些参数进行直接修改吗?不能,因为模型过于复杂,人不可能直接理解这些参数的含义,改参数毫无意义。
因此文章提出,要实现 CSI,首先:
1. 模型需要对外暴露可解释的 hook
hook 直接翻译理解,就是钩子。交互改变 hook,hook 来改变模型推理过程。在机器学习模型中,这个 hook 就是模型中的潜变量。通过修改潜变量的值,模型的推理过程也会发生变化。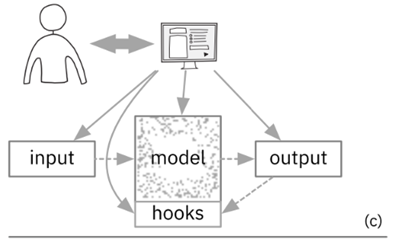
用形式化语言表达就是:假设模型中存在潜变量 z,那么推理过程就是求输出 y 关于输入 x 和潜变量 z 的分布,即
同时这个潜变量也一定是可解释的。以下图中自动驾驶火车为例,在正向推理过程中,火车在左图左边的情况时,我们无法判断火车往左还是往右,更不可能控制。而左图右边的推杆,就是一个可解释的潜变量,它暴露在模型之外,用户通过交互,可以改变推杆的方向,从而影响模型的推理过程。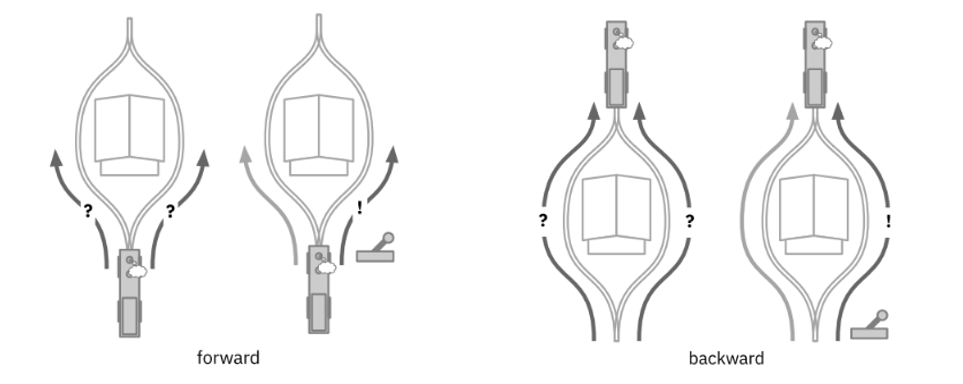
再看 backward 的部分。如果没有 hook,当火车到达右图左边所示位置时,我们无从得知,火车是从左边过来的还是右边过来的。而通过求潜变量 z 的后验分布,即
根据推杆的值,就可以知道火车是如何到达当前位置的,即模型是如何推理到当前结果的。
2. hook 要和人的心理模型相关联
毕竟 hook 是给人用的,需要符合人的心理直觉,不用多解释。
3. 通过合适的视觉隐喻,将 hook 和交互关联起来
有了 hook 如何做可视化设计,应该无需多做解释。
3.3 再看 CSI 是什么
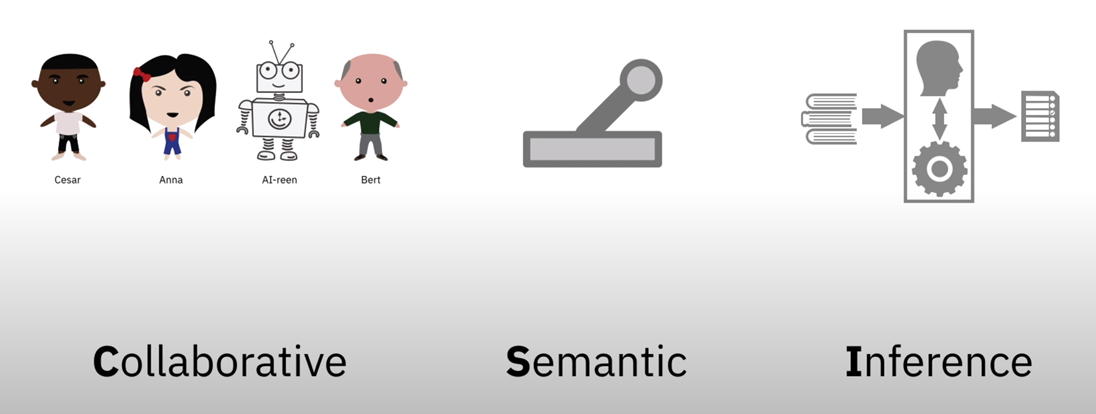
如图,CSI 的三个单词:
Collaborative,协作式的。让机器和人协作起来。
Semantic,语义的。指 hook 具备人能理解的语义。人和模型之间通过这样一个能共同能理解的语义,建立起共同语言,从而能够进行合作。
- inference,推理。人和模型共同完成推理。
4. Use Case —— document summarization
作者除了提出 CSI 这套路概念,也实现了一个 CSI 的 case:文本总结系统。它的模型输入是一段文本,输出是对这段文本的简要总结。
如果使用过去 interactive observation 的可视化工具做这件事情,用户可以向输入框中复制一段文本,然后模型给出输出结果。但是当用户觉得输出不太好,想进行改进时,就需要自己进行重新编辑,无法复用模型;而当模型输出是错的时候,用户只能选择自己重写。
4.1 功能演示
而通过 CSI 实现的文本总结系统,是这样的: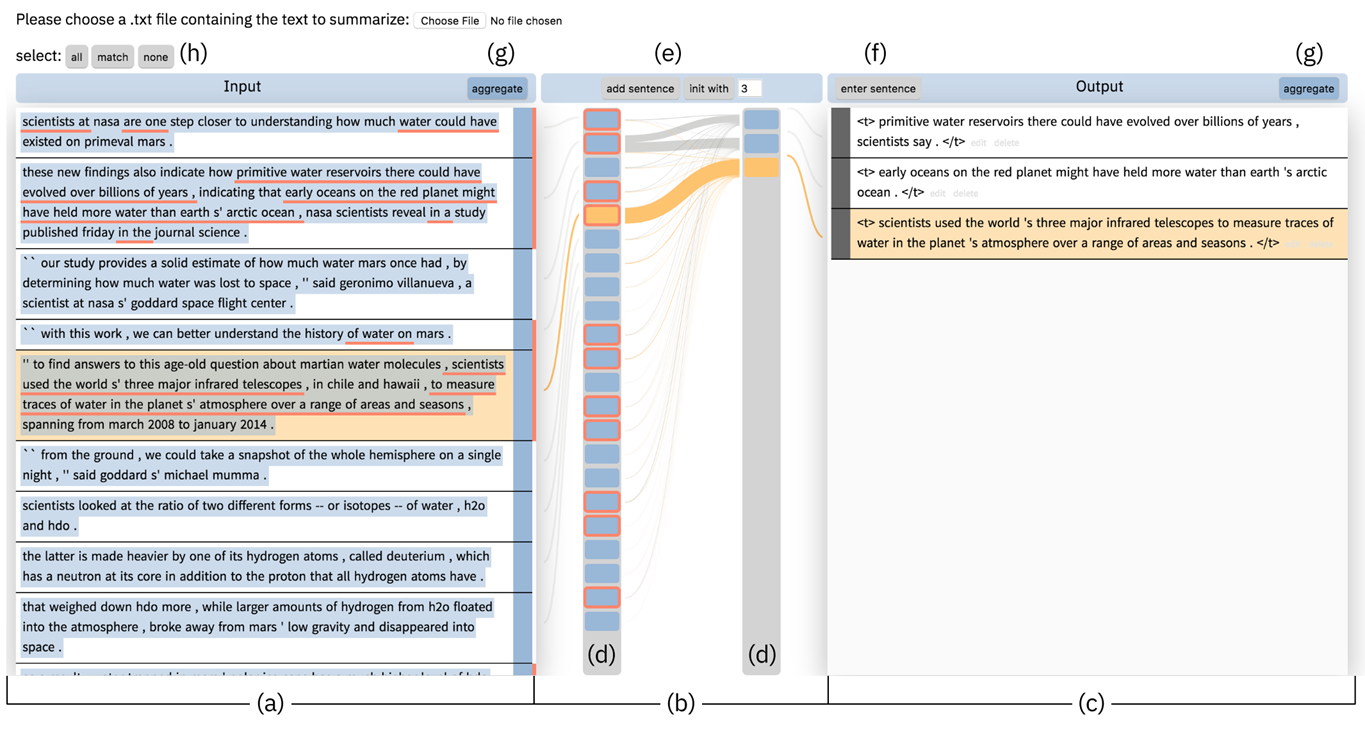
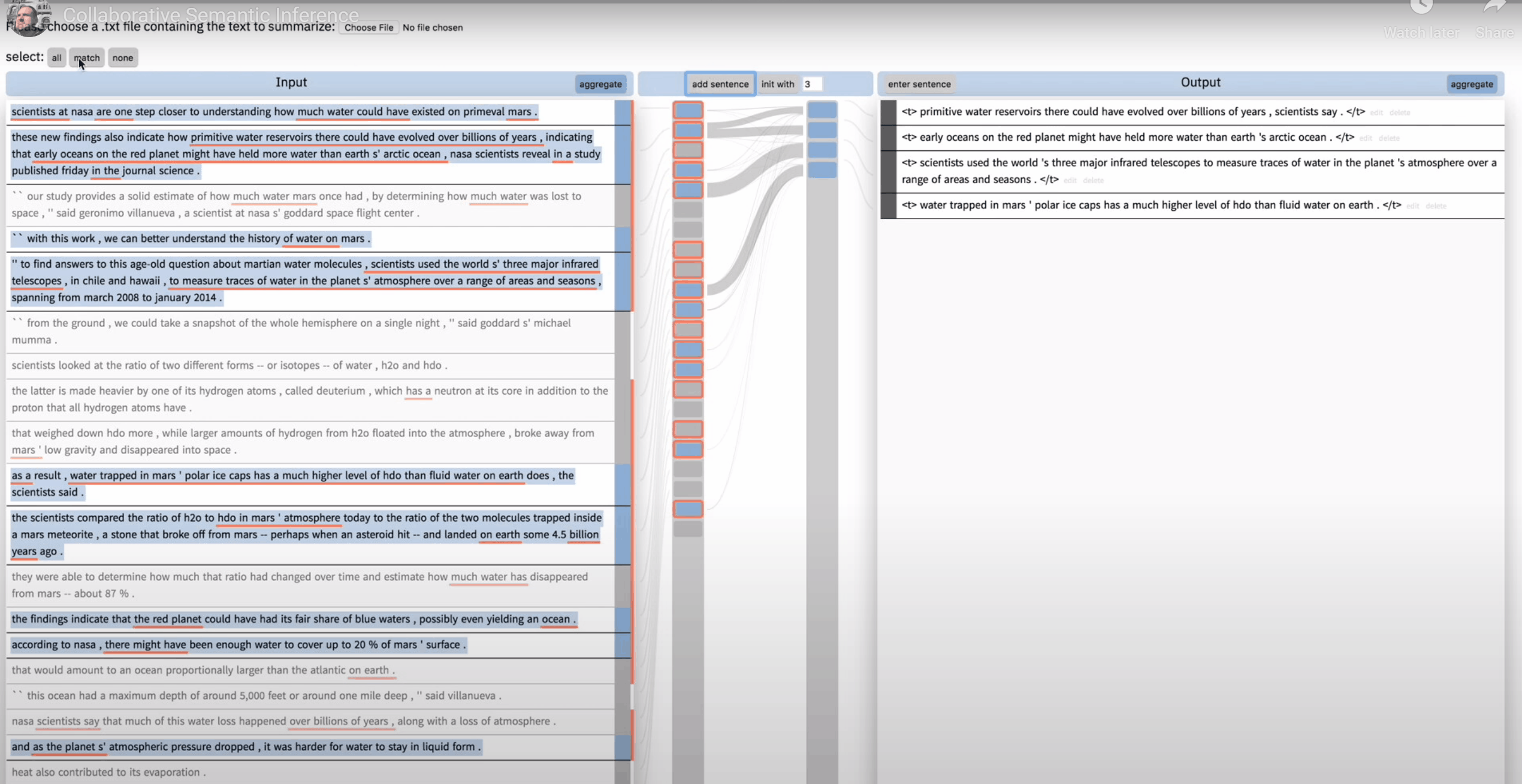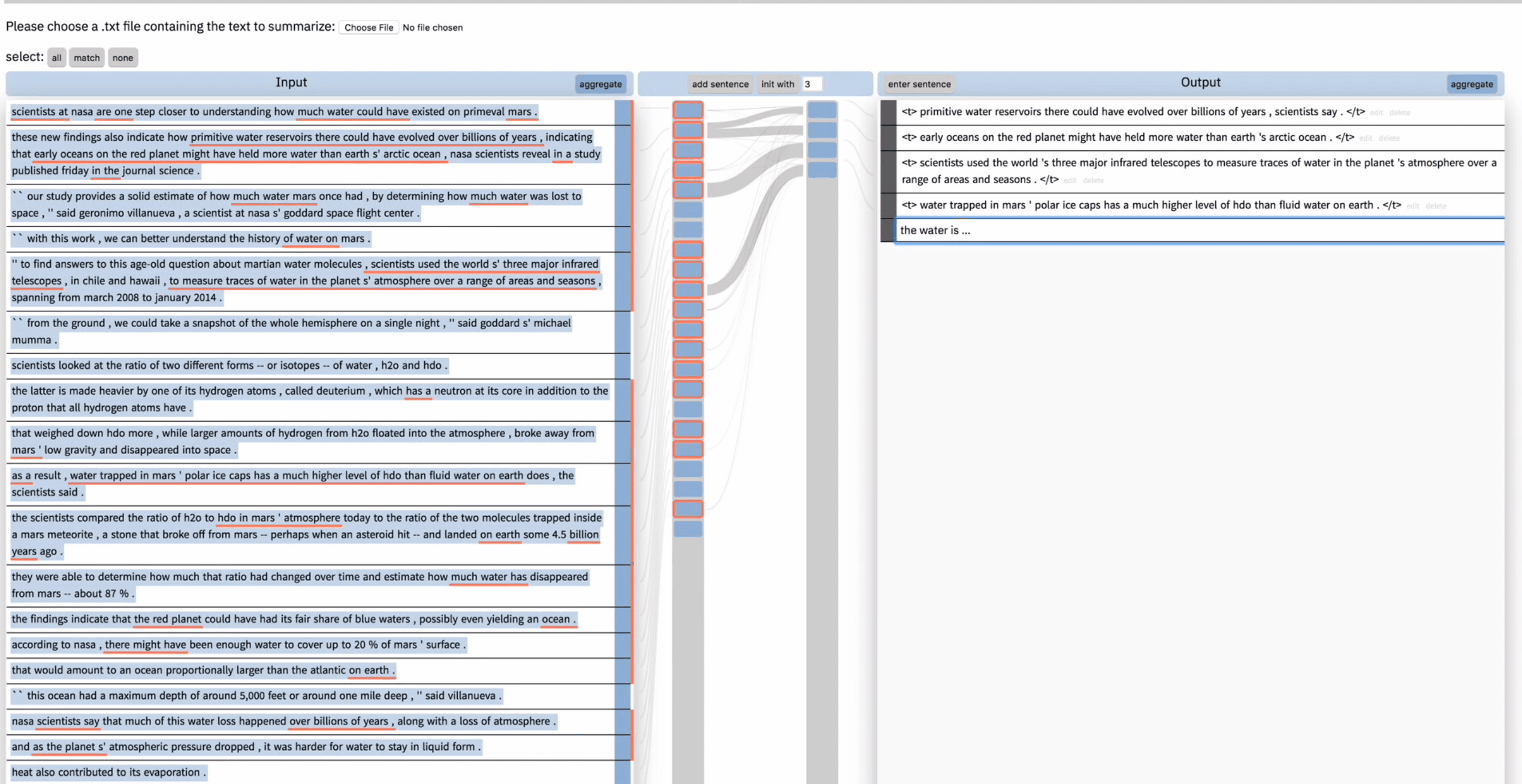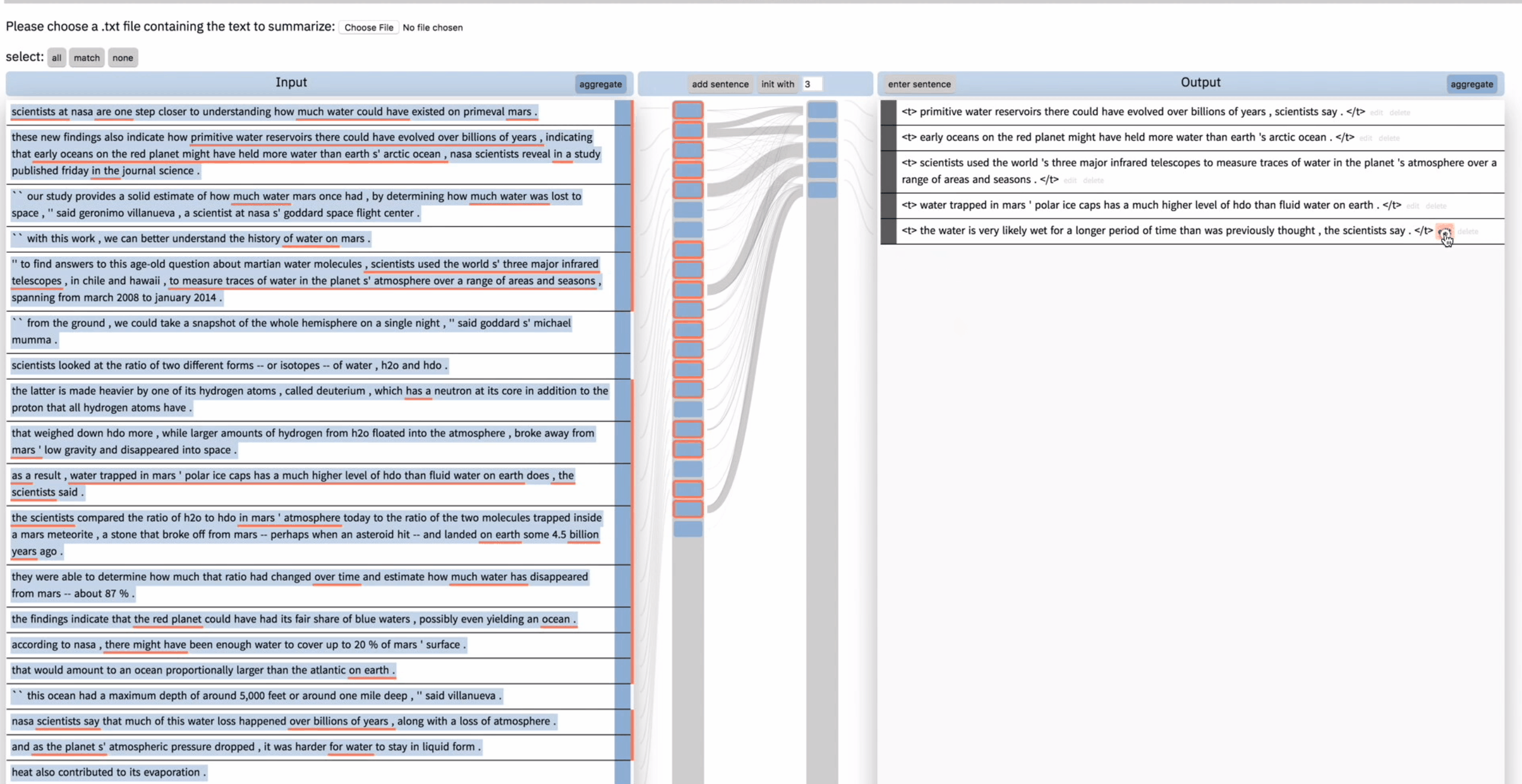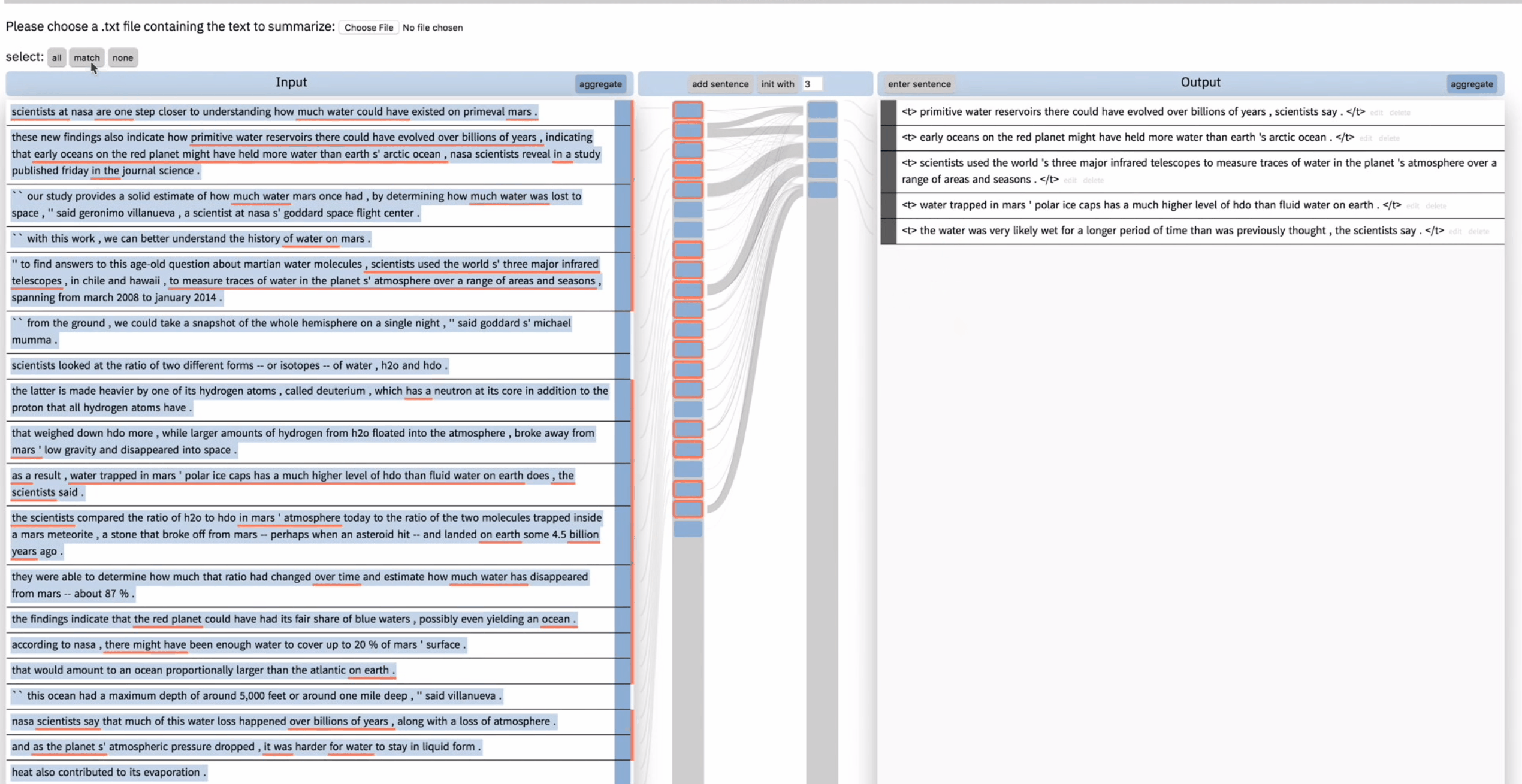
如图,a 处是输入文本,c 是输出文本,用户可以点击 e 处的”init with”来让模型初步生成几句 summary,点击 add sentence 可以让模型再添加一句 summary。b 处可视化了模型中的注意力,使得用户能够看到当前输出结果是哪些输入所影响的。
d 中的色块对应每一段文本,蓝色表示当前选择的输入语句,如果用户 unselect 了某个输入,这个输入文本就不会被模型 summary。注意,用户 unselect 了某个输入,这个输入依然会作为模型的输入,只是输出中不会出现它。这就是通过 hook 来改变推理过程而做到的 forward 过程。具体原理下节解释。
d 中红色边框表示文本被 summary 考虑,a 中红色下划线表示相应的单词被 summary 所考虑。这就是 backward,即给定输出,能够给出推理路径。
点击 h 中的 all、match、none 可自动对文本进行全选、只选当前被 summary 考虑的、全不选。
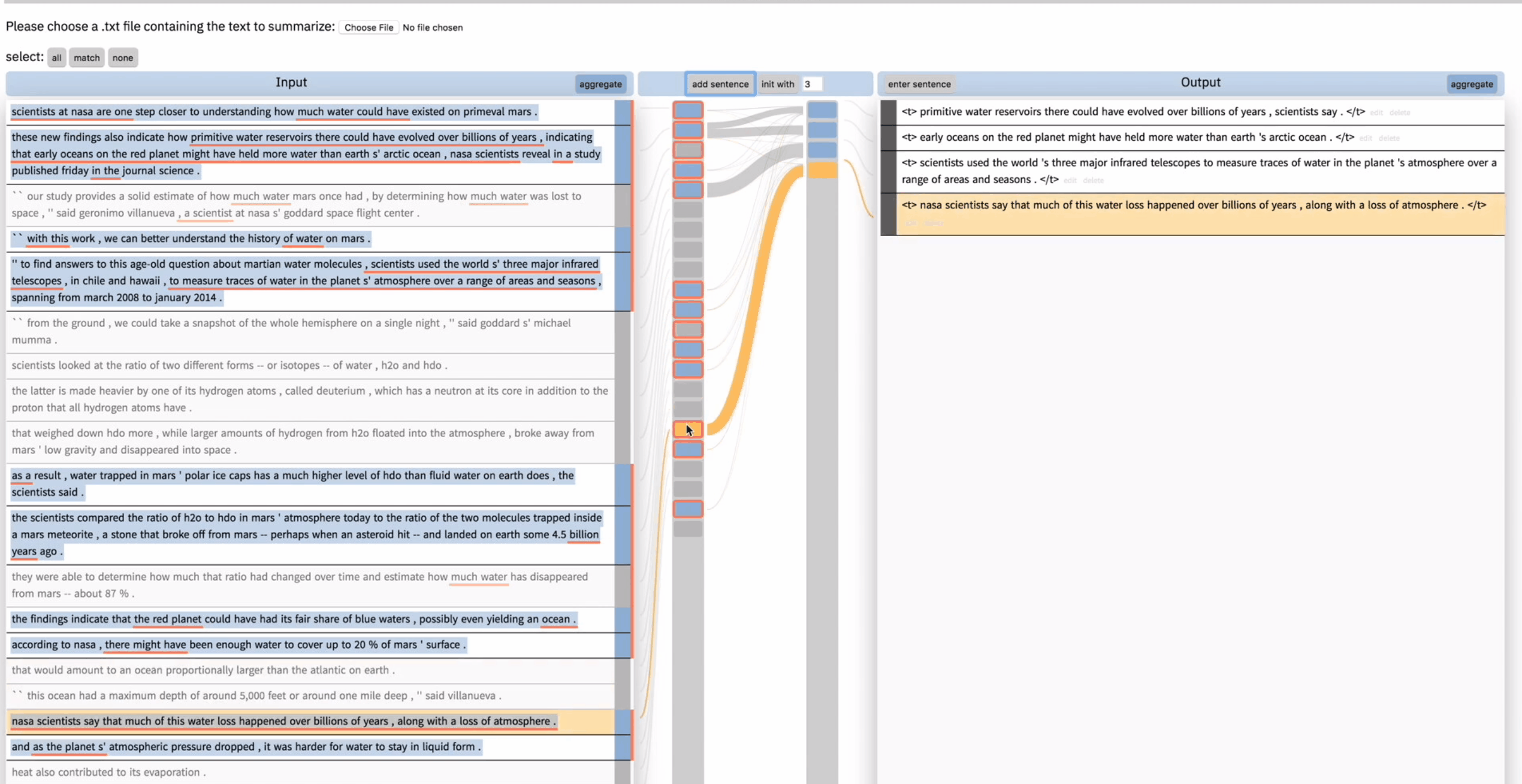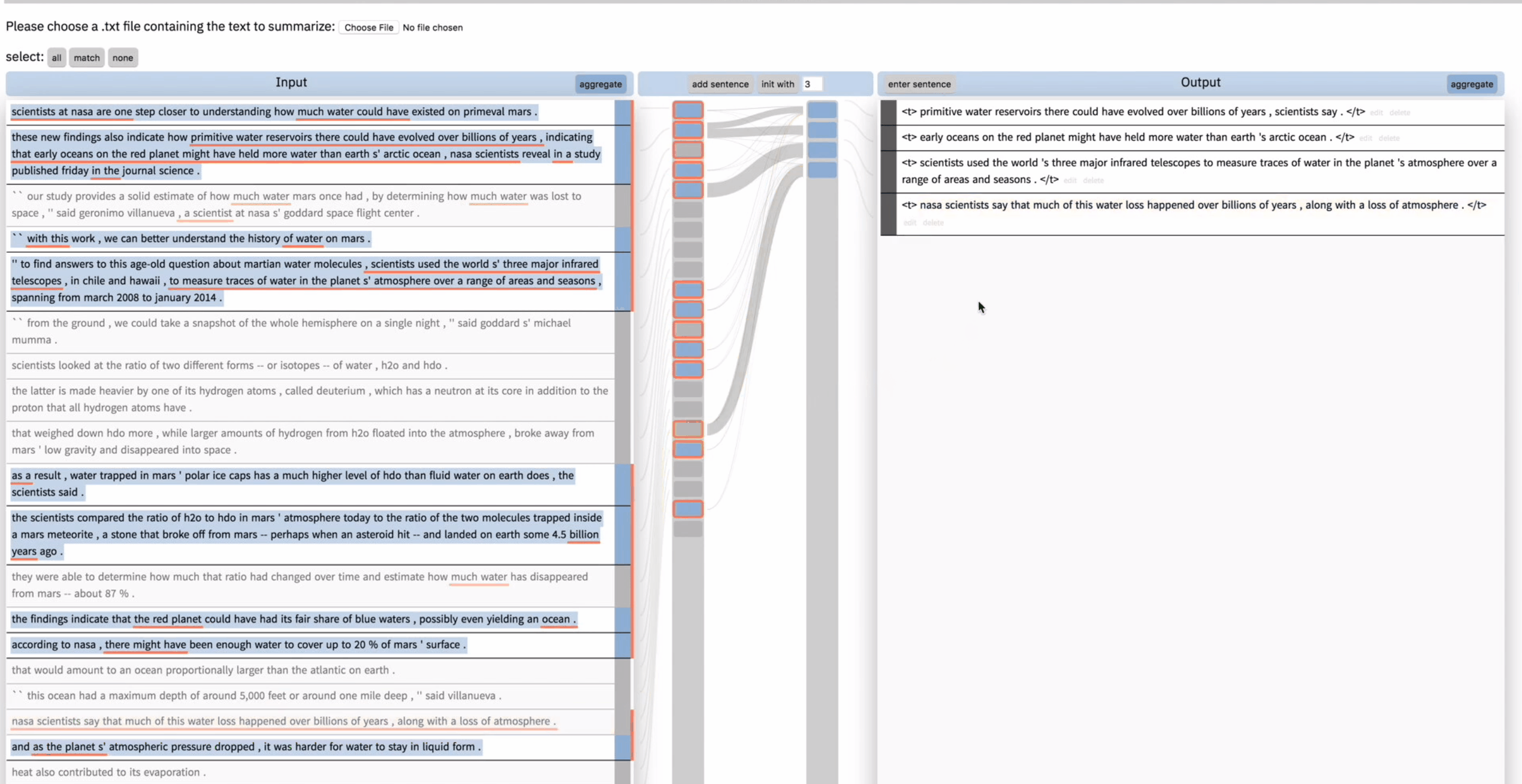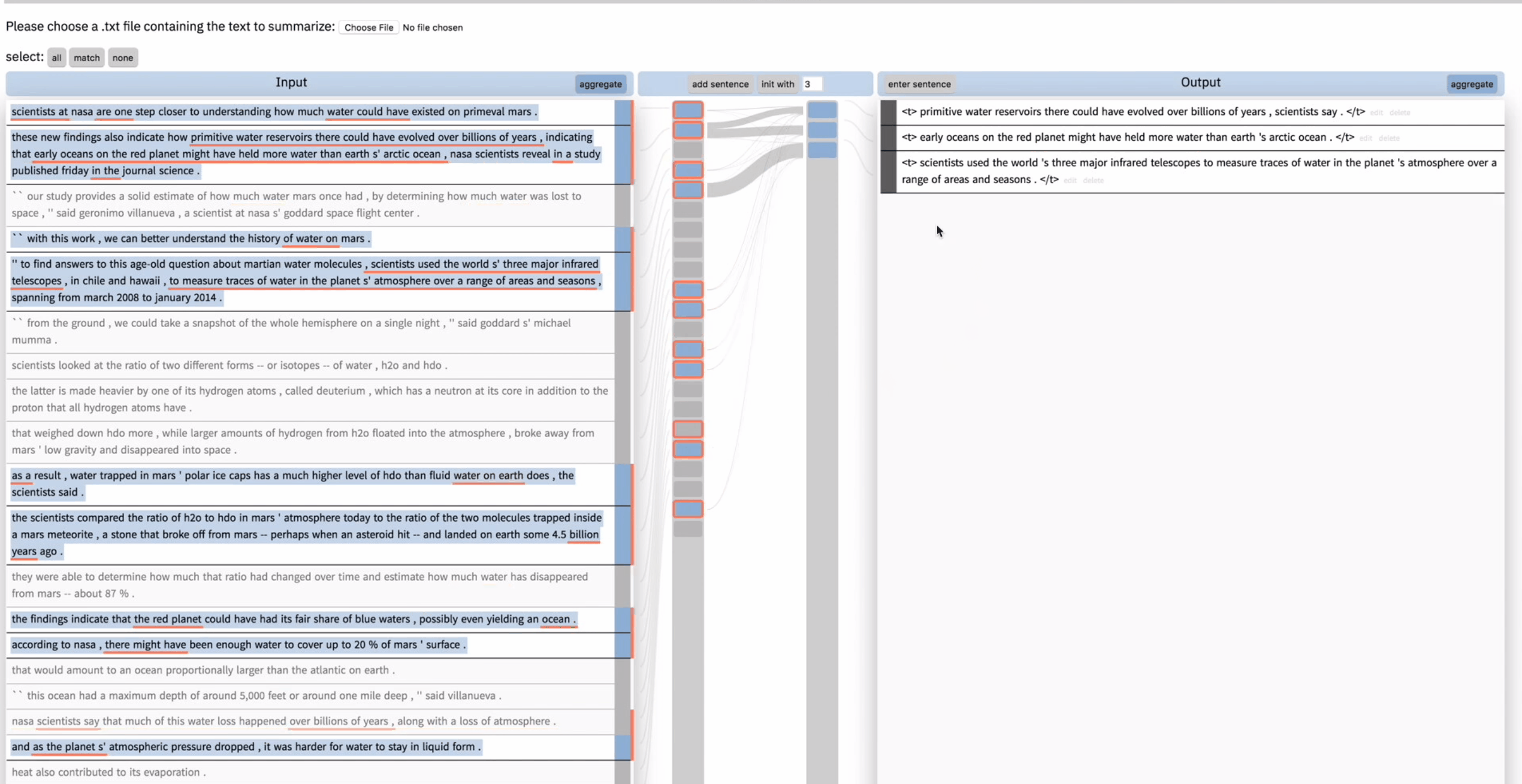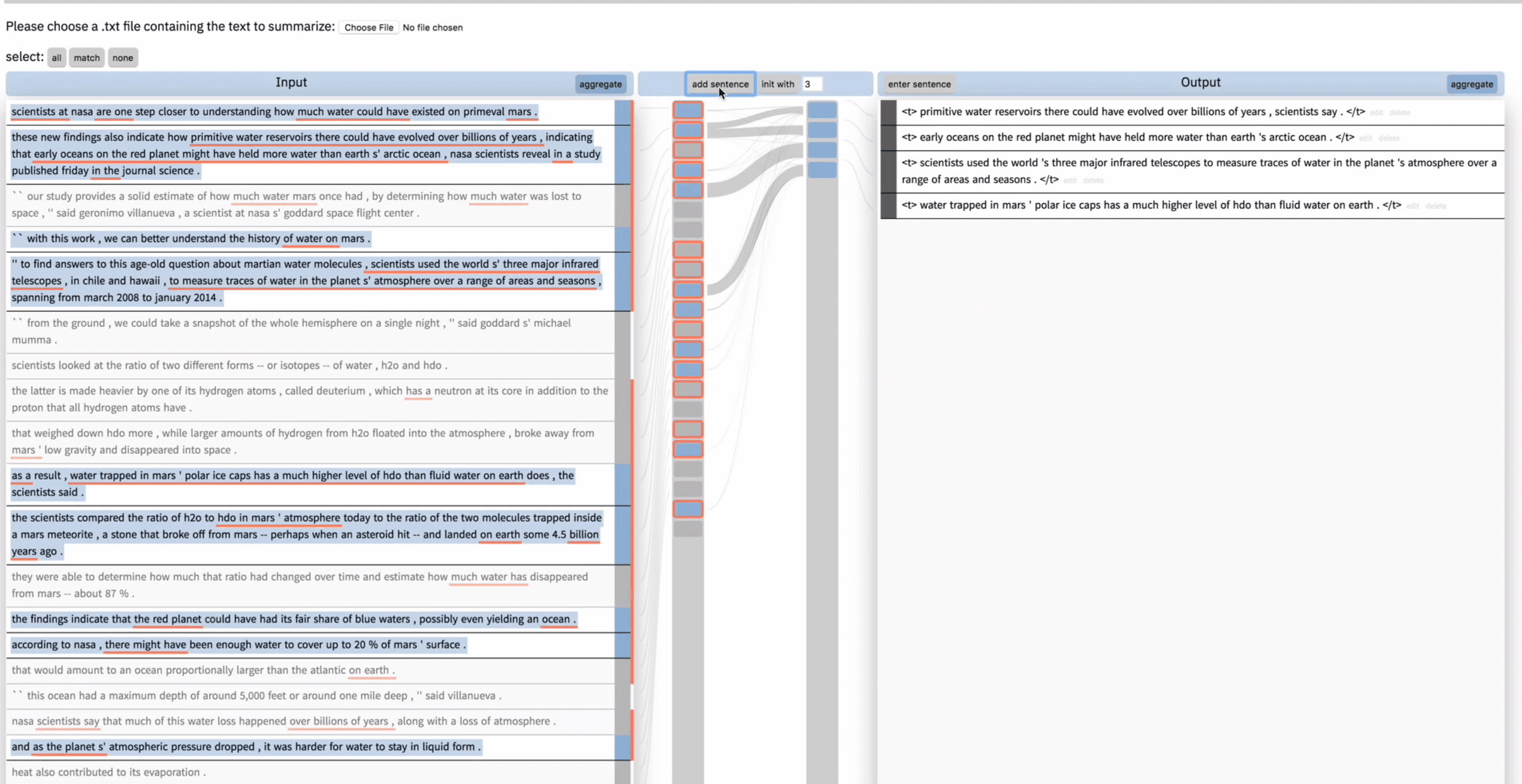
接下来我们以一个用户协作式总结”How scientist found water on Mars”为例:
如上图,用户想从当前被输出考虑到输入中再总结一句,于是他点击 match,来只选择当前被考虑的,然后点击 add sentence,模型又生成了一句 summary。
但是用户对这句新生成的总结并不满意,于是 unselect 了导致这句总结的输入,然后在右边将这句总结删掉。然后再次点击 add sentence,这次模型给出了一个不同的总结。用户表示很满意。
此时用户还想添加一句,他先全选了输入文本,然后在输出文本中输入”the water is …”,模型的自动不全功能根据当前用户的输入又产生了一句新的总结。
4.2 如何实现的
作者是如何实现模型中的 hook 来控制某些输入文本不被考虑进输出呢?
事实上这几位作者在 2018 年提出了一种文本总结架构。(S. Gehrmann, Y. Deng, and A. Rush. Bottom-up abstractive summarization. In Proceedings ofthe 2018 Conference on Empirical Methods in Natural Language Processing, pp. 4098–4109, 2018.)这种架构使用了带有 copy-attention 机制的 seq2seq 模型,这种模型中恰好有一组潜变量,每个潜变量对应一个输入单词,它控制了该单词的 attention 是否会被复制到模型的 decoder 中,这就控制了输入文本是否会被考虑进输出。
这组潜变量被暴露出模型,即 hook,用户通过交互来修改它们,这就构成了 CSI 中的 forward 过程。
另一方面,该模型在给定 x,y 时,能够方便的求出潜变量的分布,即,因此用户能够从界面中看到是哪些输入单词影响了输出结果,即 CSI 中的 backward 过程。
5. 总结
5.1 本文贡献
本文的主要贡献是:
- 定义了 CSI 的概念
- 给出了 CSI 的实现方法(通过可解释的 hook)
- 给出一个 CSI 的 case
5.2 笔者小结
作者的写作逻辑是:先提出 CSI 的概念,再根据 CSI 开发 use case 来说明 CSI 的有效性。但事实应该是,作者已经有了可交互的模型(copy attention 机制里的潜变量),再去拿这个模型来做交互。然后将概念扩大,提出 CSI。
我认为真的按作者的方法去做 CSI 很难。首先可解释的潜变量就很难设计,有时候可遇不可求。想像作者说的那样,共同设计模型、交互、可视化就更难了。作者的 case 更像是面向已有适合交互的模型来做交互,而非 co-design。
✉️ zerowangzy@zju.edu.cn